| Region | Node | Notes |
|---|---|---|
ap-southeast-1 |
dc2.large |
Network performance is slow, at 7.19s, rather than the usual 4.5s. |
eu-south-1 |
ra3.xlplus |
Slow disk-read benchmark, at 0.11s, vs the usual 0.05s. |
us-east-2 |
ra3.xlplus |
The slow disk-read two weeks ago (0.12s) has returned to normal (0.06s). |
Pretty quiet.
https://www.redshiftresearchproject.org/cross_region_benchmarks/index.html
| region | node | notes |
|---|---|---|
| ap-northeast-2 | ra3.xlplus | Disk-read-write still slow, 3.40/2.50s, previously 3.44/2.43s. |
| ap-south-1 | ra3.xlplus | Disk-read-write unusually slow, 3.38/2.46s, previously 2.46/0.03s. |
| ap-southeast-1 | dc2.large | Network returned to normal, 4.51/0.04s, previously 7.19/0.10s. |
| ca-central-1 | ra3.xlplus | Disk-read-write unusually slow, 3.4/2.49s, previously 2.51/0.03s. |
| eu-central-1 | ra3.xlplus | Disk-read-write still slow, 3.49/2.52s, previously also 5.22/3.54s. |
| eu-south-1 | ra3.xlplus | Disk-read-write still slow, 3.30/2.40s, previously also 3.41/2.40s. Disk-read returned to normal, 0.05/0.00s vs 0.11/0.00s. |
| eu-west-1 | ra3.xlplus | Disk-read-write unusually slow, 3.36/2.47s, previously 2.56/0.02s. |
| us-east-2 | ra3.xlplus | Disk-read-write slow for six weeks now, 3.45/2.55s, 5.21/3.54s and 3.54/2.55s (vs before that 2.38/0.01s). |
| us-west-1 | ra3.xlplus | Disk-read-write slow for six weeks now, much like us-east-2. |
| us-west-2 | ra3.xlplus | Disk-read-write unusually slow, 3.49/2.59s, previously 2.53/0.03s. |
The performance problems on ra3.xlplus for disk-read-write look to be caused by being on version 1.0.55524 or later.
https://www.redshiftresearchproject.org/redshift_version_tracker/index.html
https://www.redshiftresearchproject.org/cross_region_benchmarks/index.html
There’s something odd about the starttime column in stv_sessions.
In short, it’s a timestamp, but without the fractional part of the second, and when you use it with another timestamp, that other timestamp then loses its fractional part of the second!
https://www.redshiftresearchproject.org/system_table_tracker/1.0.56242/pg_catalog.stv_sessions.html
select
starttime as starttime,
timeofday()::timestamp at time zone 'utc' as timeofday,
extract( epoch from (timeofday()::timestamp at time zone 'utc') ) as epoch_timeofday,
extract( epoch from starttime ) as epoch_starttime,
timeofday()::timestamp at time zone 'utc' - starttime as "timeofday-starttime",
extract( epoch from (timeofday()::timestamp at time zone 'utc' - starttime) ) as "epoch-tod-startime"
from
stv_sessions
order by
starttime;
starttime | timeofday | epoch_timeofday | epoch_starttime | timeofday-starttime | epoch-tod-startime
---------------------+-------------------------------+------------------+-----------------+---------------------+--------------------
2023-09-16 07:35:49 | 2023-09-16 21:41:07.385411+00 | 1694900467.38542 | 1694849749 | 50718385418 | 50718
2023-09-16 07:35:49 | 2023-09-16 21:41:07.385329+00 | 1694900467.38535 | 1694849749 | 50718385363 | 50718
2023-09-16 07:37:02 | 2023-09-16 21:41:07.385396+00 | 1694900467.3854 | 1694849822 | 50645385403 | 50645
2023-09-16 07:37:02 | 2023-09-16 21:41:07.38538+00 | 1694900467.38538 | 1694849822 | 50645385388 | 50645
2023-09-16 07:37:33 | 2023-09-16 21:41:07.385426+00 | 1694900467.38543 | 1694849853 | 50614385434 | 50614
2023-09-16 07:37:46 | 2023-09-16 21:41:07.385441+00 | 1694900467.38544 | 1694849866 | 50601385448 | 50601
2023-09-16 07:41:36 | 2023-09-16 21:41:07.385484+00 | 1694900467.38549 | 1694850096 | 50371385491 | 50371
2023-09-16 20:37:55 | 2023-09-16 21:41:07.385455+00 | 1694900467.38546 | 1694896675 | 3792385462 | 3792
2023-09-16 21:39:01 | 2023-09-16 21:41:07.38547+00 | 1694900467.38547 | 1694900341 | 126385477 | 126
(9 rows)(a.k.a. svv_table_info computes unsorted
incorrectly)
I’ve been noticing that people are using the unsorted
column in svv_table_info to judge how sorted a table
is.
I think this column is absolutely incorrect, and it strongly over-states how sorted a table is.
Here’s the SQL;
Here’s the code (which I’ve partially reformatted, for readability);
CASE
WHEN (row_d.tbl_rows = 0) THEN CAST(NULL AS numeric)
WHEN (strct_d.n_sortkeys = 0) THEN CAST(NULL AS numeric)
ELSE CAST((((CAST((CAST((row_d.unsorted_tbl_rows) AS numeric)) AS numeric(19, 3)) / CAST((CAST((row_d.tbl_rows) AS numeric)) AS numeric(19, 3)))) * CAST((100) AS numeric)) AS numeric(5, 2))
END AS unsortedLet’s simplify that ELSE and get rid of unnecessary
casts and excess brackets and see what we get;
( row_d.unsorted_tbl_rows::numeric(19, 3) / row_d.tbl_rows::numeric(19, 3) ) * 100::numeric )::numeric(5, 2)Now, unsorted_tbl_rows and tbl_rows are
computed by figuring out unsorted and total row counts on a per-slice
basis and sum()ing them, like so;
sum(inner_q.slice_rows) AS tbl_rows,
sum(inner_q.unsorted_slice_rows) AS unsorted_tbl_rows,So we can now see what svv_table_info is doing.
It divides the number of unsorted rows in the table, by the total number of rows in the table, and declares that to be how unsorted the table is.
To my eye, this approach is fundamentally incorrect because a table is as slow as its slowest slice.
Consider; imagine we have a cluster with 10 slices, and a table which on 9 slices is 100% sorted and on 1 slice is 0% sorted.
Now, that table when queried runs with the speed of the 0% sorted slice, because although the other 9 slices finish quickly, it just doesn’t matter - the query cannot complete until all slices have completed their work.
Looking at svv_table_info, if we imagine 100 rows per
slice, svv_table_info will say there are 900 sorted rows
and 100 unsorted rows, so the table is 100/1000 = 10% unsorted.
I would consider that table 100% unsorted, because in practical terms, in terms of actually querying that table, that is how the table is performing. At the least I would have two statistics, one for overall sortedness and one for the least sorted slice.
(Note here that VACUUM works on a slice-by-slice basis.
If you run vacuum for a while on a table, and then cancel the vacuum, so
you’ve half-vacuumed the table, what you have are that 50% of the slices
are fully sorted, and the other 50% are untouched. Auto-vacuum, when it
does run, I think does this a lot, because I suspect it normally breaks
off its work due to other queries running. What worries me quite a bit
is the idea auto-vacuum itself is using unsorted to decide
which tables to vacuum, and I think it is, because the
threshold argument to the VACUUM command
is!)
Furthermore, I think it is a mistake in the first place to use rows - measurement should be in blocks.
What we care about, when it comes to performance, is the amount of disk I/O. All disk I/O in Redshift is in blocks, and the number of rows in a slice is only somewhat related to the number of blocks. So why use rows at all? we should be measuring the number of the sorted and unsorted blocks.
Okay. So, given all this, how do we go about correctly calculating how unsorted a table is?
At first glance, the answer appears to be we compute, in terms of blocks, how sorted each slice is, and the least sorted slice is how sorted the table is, because that will be the slowest slice, and the table is as slow as its slowest slice.
This approach however does not work because of skew.
Imagine we have a cluster again with say 10 slices, where one slice has 100 blocks, and all the others have 10 blocks.
The slice with 100 blocks has 50 unsorted blocks, and all the other slices have 8 unsorted blocks.
This means the slice with 100 blocks is 50% sorted, while all the other slices are 20% sorted - seemingly worse - but the fact is the slice with 50 unsorted blocks because it has so many blocks, is going to be the slowest slice, even though it is by this way of calculating sorting, not the most unsorted slice.
Mmm. So, for a minute, let’s forget sorting - imagine for now we have a fully sorted table - and think purely about skew, to try to quantify skew properly, and then come back to sorting.
Now, ideally, a table has the same number of blocks on every slice.
This way, every slice does exactly the same amount of work, and so a query issued on such a table runs for the same length of time on every slice - there are no lagging slices, slices which have a disproportionately large number of blocks, which slow down the entire query (as a query can completely only when all slices have finished running the query).
In the worse case, all the blocks are on one slice.
Here when we issue a query one slice does all the work, and all the other slices are completely idle.
We can easily and correctly compute a skew value for every slice.
First - and note here we’re back to rows now - we know how many rows there are in the table. The ideal is every slice has the same number of rows, so we figure out how many rows each slice should have (divide total number of rows by number of slices).
The reason we’re here back to using rows is because it is very complicated - impossible, really - to work out the number of blocks which will exist from of a given number of rows in a given table. Every column will generate blocks, the number of blocks will vary by data type, by encoding, and by the sorting order. So because we cannot work out the number of blocks, necessarily, we’re back to using rows, and we compute skew in terms of rows, and have to live with using the number of rows as a proxy for the number of blocks.
So, having worked out the ideal number of rows per slice, we then look at how many rows each slice actually has.
We can then see for each slice the ratio between how many the slice should have, and how many it actually has.
That ratio is the skew value for that slice.
If the ratio is 1, then the slice has the ideal number of rows (the ratio of 1 means it has 100% of the ideal number of rows).
If the ratio were 2, then the slice has twice the the ideal number of rows (200% of the ideal number of rows).
if the ratio were 0.5, then the slice has half the ideal number of rows (and if we see a value less than 1, we necessarily are going to see values greater than one on some other slice or slices - the rows missing from the less than 1 slice have to have gone somewhere).
To my eye then skew is a per-slice value, but can produce a per-table value, which is the highest skew value, as this will be the slowest slice (as far as skew is concerned - we’re temporarily not thinking about sorting, remember? :-), and the table will be as slow as that slice.
Back over in the murky and desperate world of the Redshift system
tables, svv_table_info has a column,
skew_rows, defined as;
Ratio of the number of rows in the slice with the most rows to the number of rows in the slice with the fewest rows.
To which I can only say, “waaaat??”
We need to know is how bad the worst slice is, so involving the least sorted slice is unnecessary, and, well, it’s hard to reason about, but I suspect it messes up the result.
Consider - imagine the worse slice has say 4 times the ideal number of rows (so here we’re computing skew the way I have). That’s plain and simple and we can see directly how much skew there is.
But with skew_rows, that 4 will vary depending on how
few rows the slice with the least rows has - but we don’t care about
slices with fewer rows. They are not slowing down queries on
the table, and they make no difference to the slice with the most
rows.
To my eye, although I may be wrong, skew_rows is
actually representing two factors, and you can’t tell them
apart in the value you see, and one of those factors is irrelevant.
Right. Okay - so we can now compute skew correctly, what does it give us for computing how unsorted a slice is?
Well, in fact, I’m going to flip the playing board over by saying now I think the notions of sorted or unsorted are in fact a red herring; we’re looking at the wrong information.
You see, being sorted or unsorted in and of itself actually means absolutely nothing - the way sorting actually influences Redshift is that it affects the ordering of rows, which in turn affects the Zone Map, and it’s the Zone Map which matters, by profoundly affecting how Redshift behaves and performs.
A highly sorted table usually has very narrow value ranges in each block; an unsorted table usually has very wide value ranges in each block. The former is fantastic for the Zone Map, the latter is death and ruin.
The Zone Map will fully express the how sorted or unsorted the table is, and it will also show us, directly, how well it is working in general - and that’s what we actually care about when we’re looking to find the slowest slice.
So let’s completely forget about sorting, and start simply looking directly at the Zone Map.
All disk I/O in Redshift is in 1mb blocks (referred to simply as
“blocks”), and each value in a block has a sorting value (which is an
int8) computed (often in strange and unexpected ways) from
its actual value, and each block has stored the minimum and maximum
sorting value in that block.
When Redshift scans a table, if for example a particular value is being searched for, a block will be scanned only if the sorting value for that value lies in between the minimum and maximum sorting value for the block.
This method is actually known as min-max culling (as blocks which are not scanned have been culled).
Now, the effectiveness of the Zone Map for a block depends on the value range in that block.
The ideal block has a value range of zero - the block’s minimum value is the same as its maximum value.
The worst block has maximum possible value range, and so can never be culled.
So what we can do is look at all the blocks, which is to say, for every column and on every slice, work out the percentage of the value range for the sorting value in each block, and probably the best way to represent this information (because there can be a lot of blocks) is a histogram, where each histogram column is 10% of the value range, showing how many blocks are in each band of 10%.
(Note here a major complication is figuring out the sorting value,
for a value. The sorting value is for about half of the data types what
you would expect it to be - an int8 is simply used directly
as its sorting value - but for the other half, it’s not what
you expect, and in some cases, to my eye, the implementation is wrong;
for example, float4 and float8, both of which
can be represented fully in the sorting value, actually take the integer
part of their value and use that to sort - which means they clamp, as
the minimum and maximum value of a float4 and
float8 massively exceed the minimum and maximum values of
the int8 sorting value. It also means all fractional values
are discarded, so for example all fractions which have the integer value
0 have the same sorting value. In any event, I have investigated
sorting, and I know how the sorting value is computed for all data
types, so I can do the necessary computation.)
Now, we cannot know how much the distribution of blocks in the histogram for a column, comes from rows being unsorted vs how much comes simply from the data that is present in the column being whatever it is.
For example, it might be the column is perfectly sorted, but the data is such that each block even when perfectly sorted has a wide range of values (we might have only say five blocks, and each could have ended up with 20% of the value range).
Or it might be we had a completely unsorted column, but every single value in the column is, say, 42. Every block in the Zone Map would be perfect!
These two examples make it clear that the idea of counts of sorted or unsorted rows as a measure of sorting, where the measure of sorting is a proxy for the measure of how well the table is performing, is fundamentally unsound; performance depends on the Zone Map and sorting is only one factor affecting the Zone Map.
All we can say is that we generally expect unsorted blocks to be
worse in the Zone Map than sorted blocks, and so we can imagine to have
some idea of how much benefit we would get from VACUUM by
looking at the number of unsorted blocks in a column.
That’s all we get, from looking at and only at the count of unsorted blocks; it is a general hint about how much sorting is degrading the column. It tells us nothing about how well the columns is actually performing.
Okay, so, back to figuring things out - we now have a histogram on a per-column, per-slice basis. That’s a lot of information to take in.
We cannot make a per-slice histogram, which would blend all columns on a slice, because the characteristics of different columns are fundamentally different and cannot meaningfully be blended together.
We can make a per-table, per-column histogram, and so getting rid of slices, where we take the total blocks for each column on each slice, and produce a mean and standard deviation for the column (so, the same column, but across all slices).
These two values I suspect are a bit complicated to reason about, but let’s see where we get to.
I think the mean will express the inherent character of the data only (whether the data tends naturally to having narrow or wide value ranges in each block). It will not express skew, because the number of blocks on each slice will have been averaged out in a mean.
I think the standard deviation (SD) will express both the inherent character of the data and skew. If say one slice has most of the blocks, the SD will be large; and also, if for a column in the table the number of blocks in a given histogram column varies greatly by slice, that too will give a high SD.
However, we can compute sound per-slice and per-table skew values, so we can inspect skew directly, and if it is near 1, the idea value, then we can know a high SD represents large cross-slice variation in the Zone Map, for the table column in question.
This would be quite strange, though - if we imagine even
distribution, then all slices should get data with the same
characteristics, but if we imagine key, then we’d need to
imagine the key being such that it tends to distribute rows such that
some slices end up with a wide range of values in their blocks, and
other slices end up with a narrow range.
That could happen - we might have say a key of a person’s age, and so a column measuring say wealth would always be a very low value for people aged between say 0 and 10 - but even with this example, we should find the hash algorithm (murmur hash, I believe) should distribute the ages 0 to 10 smoothly across all slices - ah, but then we could also imagine a much large number of slices, say 100 slices, so only 10 slices are going to have those very young people anyway.
So when we come to compute the mean/SD, we need to ignore slices which have no blocks. They are not actually participating in the column - ah, but thinking about it, we DO care if this is happening (although we need to think how to represent it), because if only a few slices have blocks, that’s really bad; most of the cluster is idle, only a few slices are actually doing work.
But I think here a percentage measure, or a direct measure (“10/100”) of slices which hold blocks is the best approach, and the slices not participating are omitted from the Zone Map calculations. This way we separate out this factor, rather than having it make the Zone Map information harder to reason about.
Okay.
Where does this leave us then, in the end, in our quest to find the slowest slice, and to define how we represent unsortedness?
Well, when I get a bit of time, I will pull all of of this together, come up with a design, and implement it in Combobulator.
In the system tables, rdsdb, the root user owned by AWS,
can access everything. Superusers can access some tables, and can view
all rows in the tables they can view. Normal users can view some tables
(less than superusers) and can view only rows which are for their own
data - where they are the owner.
You can grant select to normal users, to let them view
rows in tables which normally only superusers (and rdsdb of
course) can view.
You can also grant to a role the priv
access system tables, which means the user can access all
system tables available to superuser, and you can alter the user to have
syslog unrestricted, which allows access to all rows…
…except this has not been implemented correctly.
A number of new system tables, made by the Redshift devs, are veneer views over row-producing functions.
Those views do honour access system table - you can
select - but they do not honour syslog unrestricted - you
still cannot see all rows. Only a superuser can see all rows.
This I’ve run into for getting columns in late-binding views, and now
(prompting this post) I run into it working with external schemas and
tables. I can’t view the external tables in the system, even though I
hold access system tables, because
svv_external_tables is formed by the union of the output
from two functions (pg_get_external_tables() and
pg_get_external_database_tables(), which is making me
wondering what’s going on - maybe one function for Athena and one for
Hive?)
So for some information, natch, you still need to be superuser.
I’ve started to looking at writing Combobulator pages for external databases/schemas/tables.
Looking now at what the system tables have to offer, I may be wrong, but I think the system tables are fundamentally flawed - it is impossible to always be able to tell one external table from another.
This needs some explanation, especially so as the docs and the approach RS took to externals is to attempt to obscure, presumably in the name of simplification, but to my eye they’ve messed it up, and now it’s just confusing and unclear.
To begin with, we have the concept of external databases.
These are the entities where we will either find pre-existing information about external tables, or where we will write our own information about external tables.
We do not directly make external databases - this is actually done
via the create external schema command - because an
external schema is not a schema at all. What it actually is, is a
pointer to an external database. You can have any number of external
schemas, all of which could be pointing at the same external database,
and so all of those schemas will contain the same external tables,
because it’s the database which holds that information and all
of the schemas are pointing to the same database.
When you issue create external schema, and create a
pointer to an external database, you can either point to an existing
external database, or you can instruct Redshift to create an external
database (which will get you an Athena database).
Once we have a database, and a schema which points at it, if it’s a pre-existing database (say, a Hive database) then there may well be existing tables in the database already. If we’ve made our own external database, or we used an existing external database which is empty, in which case we have a blank slate.
In either case, we can now issue
create external table.
When we issue this command, we specify a external database where we will store the definition of the table (by dint of specifying an external schema), and we will define the table - column names and data types, some other stuff, but in particular the location of the data the external table is reading, which will often be an S3 key prefix (i.e. the common “path” part of a set of S3 keys).
Now, we see here a parallel with external tables to external schemas; if we have two or more external tables using the same location, they are reading the same data. They are in fact the identical - it’s just their external database, schema, and table name may all differ.
What really defines an external table are the columns in the table, and the location of the data. I say the columns, because I’m pretty sure (not checked) we can with some data formats (parquet for example) select which columns we use, so two external tables pointing at the same data, but with different columns, well, are they identical or not?
However, it’s not this simple (not that this is simple).
We can add external partitions to external tables.
What this means is, we can add to an external table additional locations where data is stored.
So we could start with two identical tables - maybe different database and schemas, but let’s say the same columns, and definitely the same location for their data.
Then we add a partition - a new data source - to one of those external tables.
Now the two tables are definitely different.
So what defines an external table?
Well, the external database is irrelevant - it’s the table definition which matters - and for that reason the external schema is also irrelevant, it just points at an external database.
To my eye what matters are the columns in the external table, and the full set of its original location (when it was defined) and all partitions which are then added.
Now we come to the killer problem in the system tables.
The location path for a partition is limited to 128 bytes.
So if you have location paths which share a common 128 byte prefix, you cannot tell them apart, and that means any external tables using them cannot be distinguished between on the basis of those location paths.
I could be wrong, but it looks to me like I’ve found a particular situation where the system tables are recording the wrong table ID.
All table names are changed to protect the innocent.
So, I have a table, a normal user table, on a cluster,
reddwarf.skutters. Here it is;
edh=# select trim(nspname), reloid, relcreationtime from pg_class_info, pg_namespace where relname = 'skutters' and pg_class_info.relnamespace = pg_namespace.oid;
btrim | reloid | relcreationtime
------------+---------+----------------------------
reddwarf | 1440340 | 2021-10-11 07:26:32.492703
(1 row)So the table ID is 1440340. It’s been around for a
couple of years.
Now I was looking to see if this table was in use, and lo and behold,
I found it had been queried about two days ago. That’s odd, and
expected, but here’s stl_scan;
edh=# select count(*) from stl_scan where tbl = 1440340;
count
-------
4
(1 row)Well, no doubt about it, there’s been a scan on that table.
Let’s get the query ID.
edh=# select query from stl_scan where tbl = 1440340;
query
-----------
251648606
251648606
251648606
251648606
(4 rows)Let’s go look at the query text, in stl_query.
select trim(querytxt) from stl_query where query = 251648606;And we get… this!
INSERT INTO "bluedwarf"."vending_machine" ("identifier","couponId","utilisationDate","assignmentDate","state","assignee") VALUES ( $1 , $2 , $3 , $4 , $5 , $6 ),( $7 , $8 , $9 , $10 , $11 , $12 ),( $13 , $14 , $15 , $16 , $17 , $18 ),( $19 , $20 , $21 , $22 , $23 , $24 ),( $25 , $26 , $27 , $28 , $29 , $30 ),( $31 , $32 , $33 , $34 , $35 , $36 ),( $37 , $38 , $39 , $40 , $41 , $42 ),( $43 , $44 , $45 , $46 , $47 , $48 ),( $49 , $50 , $51 , $52 , $53 , $54 ),( $55 , $56 , $57 , $58 , $59 , $60 ),( $61 , $62 , $63 , $64 , $65 , $66 ),( $67 , $68 , $69 , $70 , $71 , $72 ),( $73 , $74 , $75 , $76 , $77 , $78 ),( $79 , $80 , $81 , $82 , $83 , $84 ),( $85 , $86 , $87 , $88 , $89 , $90 ),( $91 , $92 , $93 , $94 , $95 , $96 ),( $97 , $98 , $99 , $100 , $101 , $102 ),( $103 , $104 , $105 , $106 , $107 , $108 ),( $109 , $110 , $111 , $112 , $113 , $114 ),( $115 , $116 , $117 , $118 , $119 , $120 ),( $121 , $122 , $123 , $124 , $125 , $126 ),( $127 , $128 , $129 , $130 , $131 , $132 ),( $133 , $134 , $135 , $136 , $137 , $138 ),( $139 , $140 , $141 , $142 , $143 , $144 ),( $145 , $146 , $147 , $148 , $149 , $150 ),( $151 , $152 , $153 , $154 , $155 , $156 ),( $157 , $158 , $159 , $160 , $161 , $162 ),( $163 , $164 , $165 , $166 , $167 , $168 ),( $169 , $170 , $171 , $172 , $173 , $174 ),( $175 , $176 , $177 , $178 , $179 , $180 ),( $181 , $182 , $183 , $184 , $185 , $186 ),( $187 , $188 , $189 , $190 , $191 , $192 ),( $193 , $194 , $195 , $196 , $197 , $198 ),( $199 , $200 , $201 , $202 , $203 , $204 ),( $205 , $206 , $207 , $208 , $209 , $210 ),( $211 , $212 , $213 , $214 , $215 , $216 ),( $217 , $218 , $219 , $220 , $221 , $222 ),( $223 , $224 , $225 , $226 , $227 , $228 ),( $229 , $230 , $231 , $232 , $233 , $234 ),( $235 , $236 , $237 , $238 , $239 , $240 ),( $241 , $242 , $243 , $244 , $245 , $246 ),( $247 , $248 , $249 , $250 , $251 , $252 ),( $253 , $254 , $255 , $256 , $257 , $258 ),( $259 , $260 , $261 , $262 , $263 , $264 ),( $265 , $266 , $267 , $268 , $269 , $270 ),( $271 , $272 , $273 , $274 , $275 , $276 ),( $277 , $278 , $279 , $280 , $281 , $282 ),( $283 , $284 , $285 , $286 , $287 , $288 ),( $289 , $290 , $291 , $292 , $293 , $294 ),( $295 , $296 , $297 , $298 , $299 , $300 ),( $301 , $302 , $303 , $304 , $305 , $306 ),( $307 , $308 , $309 , $310 , $311 , $312 ),( $313 , $314 , $315 , $316 , $317 , $318 ),( $319 , $320 , $321 , $322 , $323 , $324 ),( $325 , $326 , $327 , $328 , $329 , $330 ),( $331 , $332 , $333 , $334 , $335 , $336 ),( $337 , $338 , $339 , $340 , $341 , $342 ),( $343 , $344 , $345 , $346 , $347 , $348 ),( $349 , $350 , $351 , $352 , $353 , $354 ),( $355 , $356 , $357 , $358 , $359 , $360 ),( $361 , $362 , $363 , $364 , $365 , $366 ),( $367 , $368 , $369 , $370 , $371 , $372 ),( $373 , $374 , $375 , $376 , $377 , $378 ),( $379 , $380 , $381 , $382 , $383 , $384 ),( $385 , $386 , $387 , $388 , $389 , $390 ),( $391 , $392 , $393 , $394 , $395 , $396 ),( $397 , $398 , $399 , $400 , $401 , $402 ),( $403 , $404 , $405 , $406 , $407 , $408 ),( $409 , $410 , $411 , $412 , $413 , $414 ),( $415 , $416 , $417 , $418 , $419 , $420 ),( $421 , $422 , $423 , $424 , $425 , $426 ),( $427 , $428 , $429 , $430 , $431 , $432 ),( $433 , $434 , $435 , $436 , $437 , $438 ),( $439 , $440 , $441 , $442 , $443 , $444 ),( $445 , $446 , $447 , $448 , $449 , $450 ),( $451 , $452 , $453 , $454 , $455 , $456 ),( $457 , $458 , $459 , $460 , $461 , $462 ),( $463 , $464 , $465 , $466 , $467 , $468 ),( $469 , $470 , $471 , $472 , $473 , $474 ),( $475 , $476 , $477 , $478 , $479 , $480 ),( $481 , $482 , $483 , $484 , $485 , $486 ),( $487 , $488 , $489 , $490 , $491 , $492 ),( $493 , $494 , $495 , $496 , $497 , $498 ),( $499 , $500 , $501 , $502 , $503 , $504 ),( $505 , $506 , $507 , $508 , $509 , $510 ),( $511 , $512 , $513 , $514 , $515 , $516 ),( $517 , $518 , $519 , $520 , $521 , $522 ),( $523 , $524 , $525 , $526 , $527 , $528 ),( $529 , $530 , $531 , $532 , $533 , $534 ),( $535 , $536 , $537 , $538 , $539 , $540 ),( $541 , $542
(1 row)So an insert has been issued on a different table,
bluedwarf.vending_machine, and from that I have a query in
stl_scan which is claiming to have read table ID
1440340?
Let’s have a look at stl_insert.
edh=# select * from stl_insert where query = 251648606;
userid | query | slice | segment | step | starttime | endtime | tasknum | rows | tbl | inserted_mega_value | use_staging_table
--------+-----------+-------+---------+------+----------------------------+----------------------------+---------+------+--------+---------------------+-------------------
101 | 251648606 | 1 | 1 | 2 | 2023-09-25 02:07:31.518827 | 2023-09-25 02:07:31.521612 | 101 | 0 | 133515 | f | t
101 | 251648606 | 0 | 1 | 2 | 2023-09-25 02:07:31.518777 | 2023-09-25 02:07:31.521611 | 92 | 0 | 133515 | f | t
101 | 251648606 | 3 | 1 | 2 | 2023-09-25 02:07:31.519151 | 2023-09-25 02:07:31.521832 | 105 | 0 | 133515 | f | t
101 | 251648606 | 2 | 1 | 2 | 2023-09-25 02:07:31.519049 | 2023-09-25 02:07:31.52716 | 113 | 100 | 133515 | f | t
(4 rows)Interesting. The final column - use_staging_table.
https://docs.aws.amazon.com/redshift/latest/dg/r_STL_INSERT.html
It’s not in the docs, but the docs are after ten years about 20% inaccurate for columns in system tables.
We can see it in system table tracker;
https://www.redshiftresearchproject.org/system_table_tracker/1.0.56754/pg_catalog.stl_insert.html
We can guess what it means - the insert has gone to staging table,
and from there that staging table has been scanned, with the rows then
being inserted into bluedwarf.vending_machine.
We can see the insert knows it is inserting to
bluedwarf.vending_machine (tbl is
133515, which is the correct table ID for this table).
So the problem looks to be that the scan of the staging table, in
stl_scan, is giving the wrong table ID.
Let’s look at what stl_scan has to actually say abouq
query 251648606.
edh=# select slice, segment, step, trim(perm_table_name) from stl_scan where query = 251648606 order by slice, segment, step;
slice | segment | step | btrim
-------+---------+------+--------------------
0 | 1 | 0 | Internal Worktable
0 | 2 | 0 | Internal Worktable
1 | 1 | 0 | Internal Worktable
1 | 2 | 0 | Internal Worktable
2 | 1 | 0 | Internal Worktable
2 | 2 | 0 | Internal Worktable
3 | 1 | 0 | Internal Worktable
3 | 2 | 0 | Internal Worktable
12825 | 0 | 0 | Internal Worktable
12825 | 3 | 0 | Internal Worktable
12825 | 4 | 0 | Internal Worktable
(11 rows)So there we go. It is an internal temporary table (slice 12825 is the leader node).
This bug is making the table look like it’s being used when it fact it is not being used, which is messing up my computation of how long tables have been idle for, where I need this calculation so I can get rid of tables which are not in use.
Redshift Serverless is not serverless. A workgroup is a normal, ordinary Redshift cluster. All workgroups are initially created as a 16 node cluster with 8 slices per node, which is the default 128 RPU workgroup, and then elastic resized to the size specified by the user. This is why the original RPU range is 32 to 512 in units of 8 and the default is 128 RPU; the default is the mid-point of a 4x elastic resize range, and a single node, the smallest possible change in cluster size, is 8 RPU/slices. 1 RPU is 1 slice. With elastic resize the number of nodes changes but the number of data slices never changes; rather, the data slices are redistributed over the new nodes, where if the cluster becomes larger, the slice capacity of each node is filled up with compute slices, which are much less capable than data slices, and where if a cluster becomes smaller, the original set of 128 data slices for 16 nodes are crammed into the remaining nodes. Both outcomes are inefficient for compute and storage; a 512 RPU workgroup has 128 data slices and 384 compute slices, rather than 512 data slices, and a 32 RPU workgroup in the worst case for disk use overhead, small tables (~150k rows), consumes 256mb per column, compared to the 64mb of a provisioned 32 slice cluster. The more recently introduced smaller workgroups, 8 to 24 RPU (inclusive both ends) use a 4 slice node and have two nodes for every 8 RPU. In this case, the 8 RPU workgroup is initially a 16 node cluster with 8 slices per node, which is resized to a 2 node cluster with 4 slices per node - a staggering 16x elastic resize; the largest resize permitted to normal users is 4x. An 8 RPU workgroup, with small tables, uses 256mb per column rather than 16mb per column. Workgroups have a fixed number of RPU and require a resize to change this; workgroups do not dynamically auto-scale RPUs. I was unable to prove it, because Serverless is too much of a black box, but I am categorically of the view that the claims made for Serverless for dynamic auto-scaling are made on the basis of the well-known and long-established mechanisms of AutoWLM and Concurrency Scaling Clusters. Finally, it is possible to confidently extrapolate from the ra3.4xlarge and ra3.16xlarge node types a price as they would be in a provisioned cluster for the 8 slice node type, of 6.52 USD per hour. Provisioned clusters charge per node-second, Serverless workgroups charge per node-query-second and so go to zero cost with zero use. On the default Serverless workgroup of 128 RPU/16 nodes (avoiding the need to account for the inefficiencies introduced by elastic resize), 10 queries run constantly for one hour (avoiding the need to account for the Serverless minimum query charge of 60 seconds of run-time) costs 460.80 USD. A provisioned cluster composed of the same nodes costs 104.32 USD. The break-even point is 2.26 queries for one hour. Serverless introduces zero usage-zero cost billing, which allows for novel use cases, but this could have perfectly well been obtained by introducing a zero-zero billing model for Provisioned Redshift, without the duplicity, considerable added complexity, end-user confusion, cost in developer time and induced cluster inefficiency involved in the pretence that Serverless is serverless.
https://www.redshiftresearchproject.org/white_papers/downloads/serverless.pdf
https://www.redshiftresearchproject.org/white_papers/downloads/serverless.html
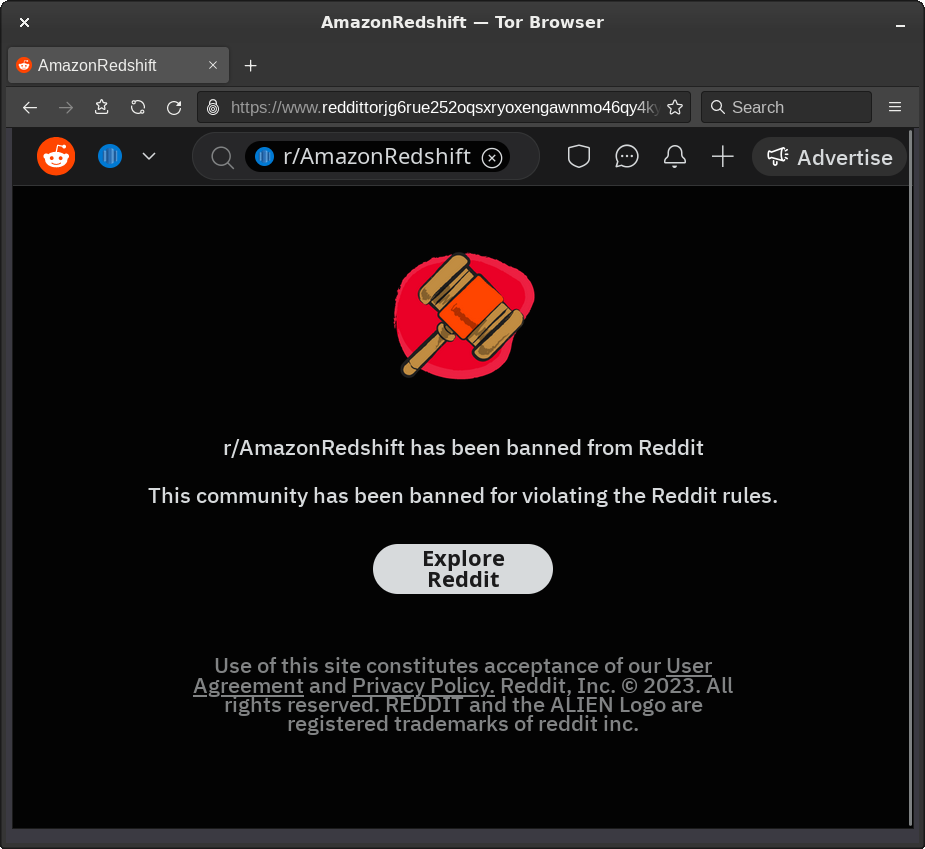
I just posted the PDF to r/AmazonRedshift on Reddit, a sub which I started about two years ago, and it is clear that making the post has directly and immediately caused the sub to be banned, so I presume an automated system has triggered the ban.
No other information, no links or information to routes to appeal, or find out what happened, or why.
This is why I implemented a forum on the RRP site. Sooner or later Reddit was going to go bad, that day has come.
I have realized my account has been deleted, or shadow-deleted; I can still log in, and I can see my profile and if when logged in I look at threads I’ve posted to, I see my posts - but if I view Reddit when I am logged out, it is then clear everything I’ve ever posted has been deleted.
I’ve not been notified of this.
It’s all pretty slimy.
If you are using Reddit, please instead keep an eye on the RRP blog, or visit the forum on the RRP site, which is here;
https://www.redshiftresearchproject.org/slforum/index.html
Home 3D Друк Blog Bring-Up Times Consultancy Cross-Region Benchmarks Email Forums IRC Mailing Lists Reddit Redshift Price Tracker Redshift Version Tracker Redshift Workbench System Table Tracker The Known Universe Twitter White Papers